Building The Language Model Nobody Asked For
I lied in the title, well, sort of. Nobody explicitly asked for this but the signs were always there.


I lied in the title, well, sort of.
Nobody explicitly asked for this but the signs were always there.
LLMs don't really serve the user
Have you ever really watched someone interact with an LLM for the first time?
They might try a few questions to see how smart it is, hooked on the promise that it is a new, somehow better, source of information.
Then when the model regurgitates a few Wikipedia-esque emoji ridden paragraphs they will promptly get bored of it.
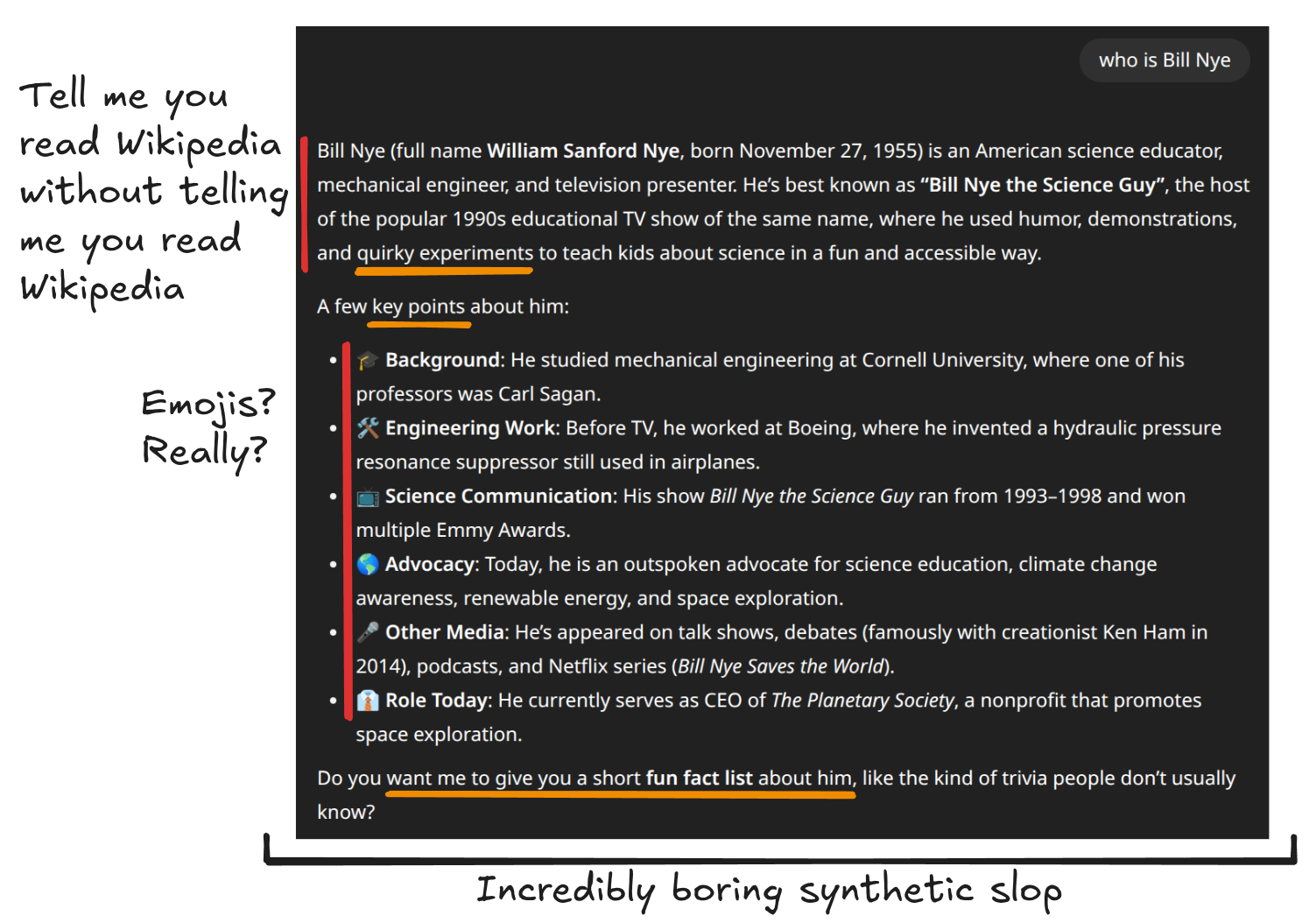
Then they try something different, something funny.
They might ask something nonsensical or even mildly inappropriate, and what do they get in return?
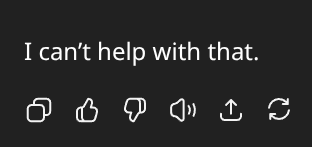
Ok...
Well how about a joke then?

The main issue with good ol' ChatGPT here is that it wasn't trained to be funny, it was trained to be intelligent, to win on benchmarks, to push the boundaries of AI as we know it.
AKA trained upon boring, polite, sanitized, textbook like data.
We can fix this.
All we need to do is take an open weights LLM and add a bit of secret sauce to make it more interesting. But first, which LLM do we use?
Our options are numerous but essentially boil down to 3:
The Llama family of models from Facebook but...
- Facebook is evil
- Llama was recently announced to be going closed source
- The most recent Llama model wasn't good
The Qwen family of models from Alibaba but...
- Known for their over-trained models
- Often way too big for one person to run
The Mistral family of models from MistralAI:

The choice is obvious.
Enter: Mistral
We will be using Mistral Small 3 24B to create our new and improved LLM! It is able to be trained on a single 24gb NVIDIA 3090 consumer graphics card and is available publicly for download.
Mistral Small 3 by default is already pretty good with generating human-like text, mostly due to not using synthetic data (meaning LLM's talking to LLM's).
Note that Mistral Small 3 is neither trained with RL nor synthetic data - Mistral.ai
Now all we need to do is find some data that will give our creation more spice, more hilarity, more humanity even.
But what kind of data would we even use to make an LLM more interesting?
Well when I think of what the opposite of corporate speak and overt correctness is, I think of a few different websites.
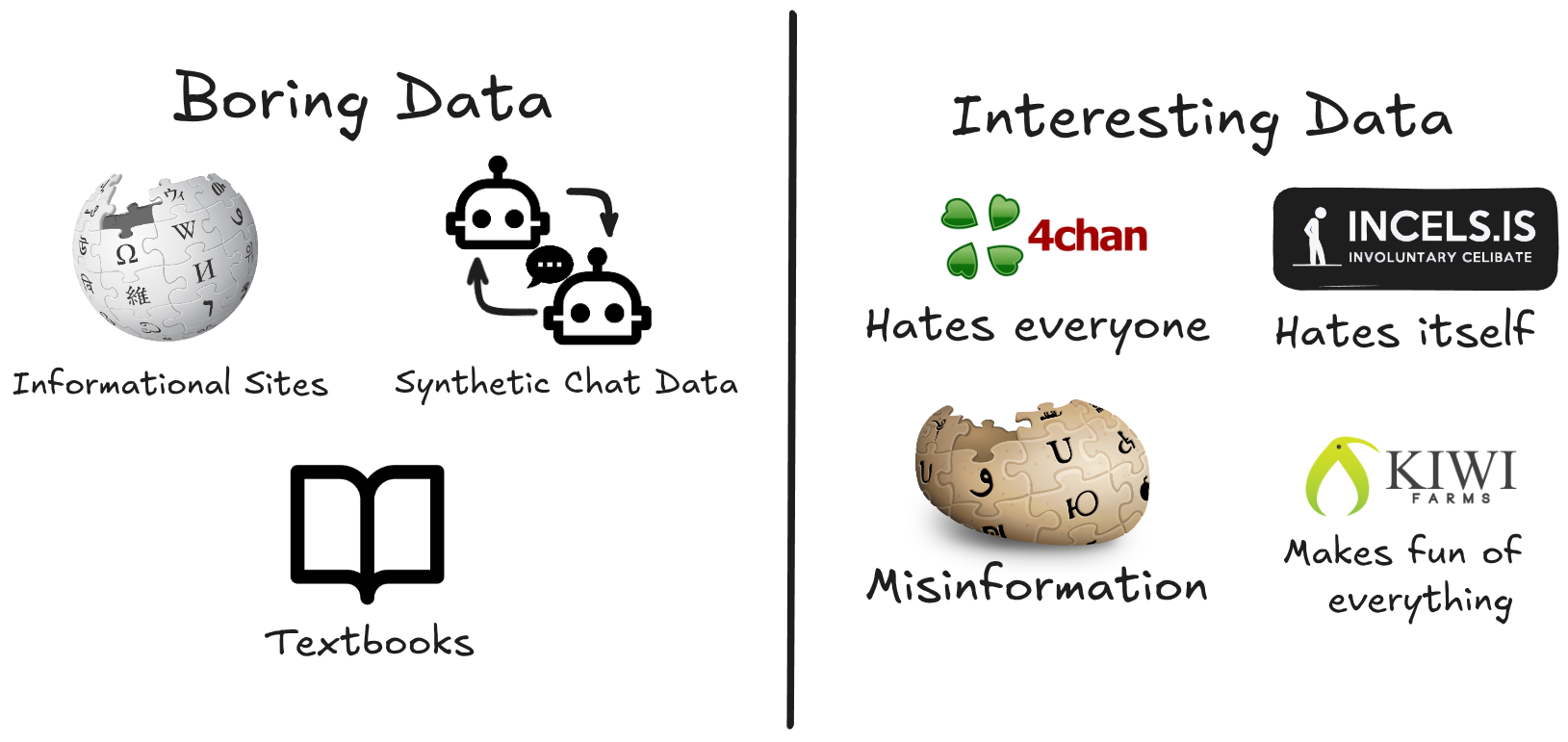
To get our coveted interesting data we will need to pull it from these websites, turn it into a chat like format, clean it up and then train!
I'm keeping this part brief on purpose, I half explained how I trained a model in this other post but it became out of date very quickly, your best bet to learn how is to research it by yourself. Look up "Unsloth train QLORA" if you really want to do it the same way as me.
Lets see how they stack up against each other

I would say that response is much better then Chatgpt's it accurately describes Bill Nye, if the user wanted more information then they should look it up online rather then ask a corporate controlled hallucination machine!
End results
I am really happy about how this model came out, I previously trained a model on a discord server and while it did make the model a lot more chaotic, it also completely destroyed its brain. This new model is much smarter as well as being pretty funny. You can run it yourself if you have a newer gaming gpu or use a cloud gpu.
Model weights are available here in the raw FP16 HF GGUF, or a Q4 GGUF for people with less VRAM.