Cloning your Discord friends with Large Language Models
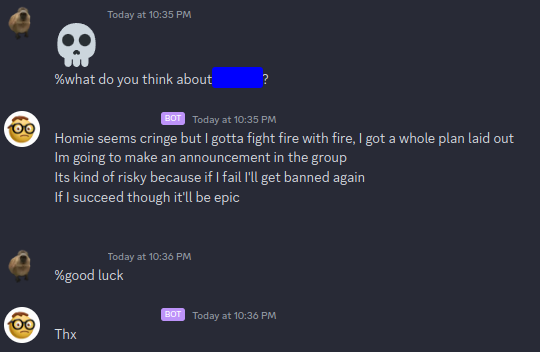
Did it work well and is it useful in any way? No. Is it hilarious to mess around with and does it mimic them well? Yes.


Did it work well and is it useful in any way? No.
Is it hilarious to mess around with and does it mimic them well? Yes.
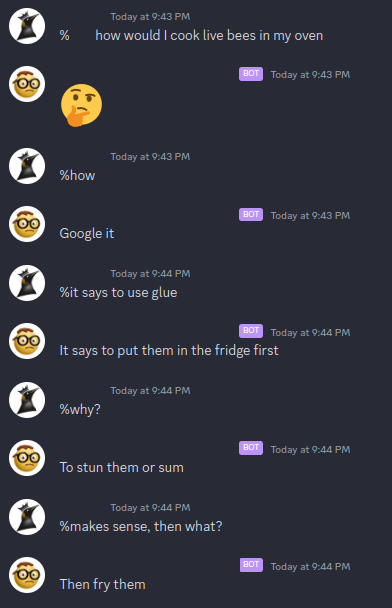
Do I need like a supercomputer or something for this?
For this project I used a single RTX 3090 that has 24GB of vram, during training my vram sat at around 22GB of usage. I'm using linux so for the people running windows you might want to check how much vram your system is using at idle to avoid running out of memory during training.
You could probably also do this on google colab for free but I chose not to because of the risk of losing my work if google decided to randomly shut off the vm I was using. Other options for renting GPU time include runpod.io or vast.ai where you can get a 3090 for around 30 cents per hour.
Why do this?
With all this new LLM technology coming out recently I thought back to the time I tried to clone my friends with GPT-2, it didn't turn out that great given GPT-2 is a very small model by today's standards.
But now that we have high quality LLMs like Mistral 7b and LLaMA 7b-70b I thought I would give it another shot.
You've done this before?
On my last attempt I formatted my dataset to just look like chat logs, it was a large text file with no formatting other then "<\username>: <message><newline>" repeated over and over. This was sub optimal because it made it really difficult to edit the dataset.
This time I did something a bit different. Here's how I got my dataset in order.
First I downloaded the discord channels that I wanted to train on in JSON format using Tyrrrz/DiscordChatExporter. I then used JEF1056/clean-discord (which is currently nonfunctional and needed a few edits to the code to get it working) to take my channel data and separate it into arrays of messages that happened around the same time, referred to as "conversations". These two tools worked really well and I now had over 200 thousand messages which sorted out nicely.
Why are we editing the dataset again?
A common term you hear in machine learning is "Garbage in, Garbage out" and this is super true for language models.
If you've been paying attention to the NLP space in recent times you might remember soon after the release of GPT3 (the one before ChatGPT) an "open and collaborative workshop" called BigScience released an LLM called Bloom which had 180 billion parameters which was around the same size as GPT3, it was handily beaten due to what I think is probably the training data.
LLM's really like data that is structured and your data quality could mean the difference between your LLM answering your questions or just replying "lol" to everything.
So what did you do to your data?
With that in mind the next thing I did was try to clean up my discord data as much as possible. I wrote a simple program in JavaScript that preforms regex operations on my data to clean it up as much as possible. Here are some of the things I did my best to filter out.
- Single ping messages "@servermember"
- Low quality conversations (Criteria is <5 messages that are all shorter then 30 characters)
- Messages containing non responses like "lmao", "lol" and "gg"
- Conversations with "conversation-enders" in them like "gtg", "I'm going to sleep" and "cya"
I also just completely removed the @ sign from every message, my first model iteration really liked sending pings and nothing else (I did not do any dataset filtering). Now it just looks like people are mentioning names instead of pinging.
And how do you get a computer to read this?
Ok so now that the data looks good we can start actually training the model!
I'm going to be using Axolotl because I've seen it mentioned a lot on r/LocalLLaMAand when I asked the smart person AI discord server KoboldAI I was told it was good.!
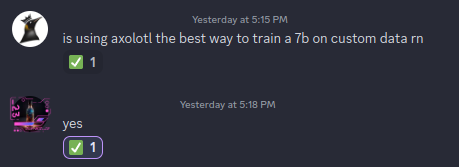
Thankfully it seems they were right.
So now I needed to get my dataset into the right format for training. Looking at Axolotl's README.md we can see the following.
(This may have changed since the making of this post, might want to check if its been a while)
Axolotl supports a variety of dataset formats. Below are some of the formats you can use.
Have dataset(s) in one of the following format (JSONL recommended):
alpaca: instruction; input(optional)
{"instruction": "...", "input": "...", "output": "..."}
sharegpt: conversations where from is human/gpt. (optional: system to override default system prompt)
{"conversations": [{"from": "...", "value": "..."}]}
Which one is better for this job?
Because of the nature of my dataset I'll be using the sharegpt format. I wrote another small JavaScript program to take each "conversation" and format it into the right format so now I have a file with each "conversation" object on its own line which is valid JSONL formatting.
How does Axolotl work?
Now looking at Axolotls README.md again we can see that there are a few ways of running it, I chose to use the docker container they provide since I already have my system set up so that docker containers can access GPU resources.
Axolotl uses a simple config file for its training jobs, it lets you specify what model you're going to be training and specify datasets to use for it. When running a training job all you have to do is pass this config file to Axolotl.
Model?
Yeah, there are a lot of different LLM models out there. A large number of them are "fine tunes" of base models that are commonly put out by corporations. Its possible to train your model on a fine tune of another model but for this project I'm going to use a base model.
Due to my limited vram the model I chose is Mistral-7b, I could have also chose LLaMA-7b but Mistral is a bit smarter and has a larger amount of text it can act on. If you have more vram and compute then me you can train on larger models like LLaMA-70b if needed.
So what's that config look like?
The config I used was the same as the example configs in Axolotls Github repo, however I specified my custom dataset
datasets:
- path: axo.jsonl
type: sharegpt
and changed num_epochs from 1 to 10 to train the model for a longer period of time. you can find the example config here.
Just send it?
All I had to do now was run it and wait. The model trained for 6 hours total, keep in mind your train time may vary based on dataset size and how many epochs you train for.
I was able to import the trained model (which is actually called a LoRA) into oobabooga/text-generation-webui which is a way you can get a quick and dirty API setup for your LLM's.
Now we build stuff off of it?
I wrote a quick discord bot that lets people talk to the AI versions of the other people in the server. Complete with inside jokes and all.